
debugging
How to Fix Tool-Use Loops in Autonomous Coding Agents
Autonomous coding agents love getting stuck in tool-use loops. Here's why it happens and four concrete fixes that stop the bleeding.
aiagentspython
Autonomous coding agents love getting stuck in tool-use loops. Here's why it happens and four concrete fixes that stop the bleeding.

LLM coding agents quietly drop constraints as tasks get longer. Here's why it happens and a concrete pattern for keeping back end code generation honest.

Why AI agents lose context across multi-step tool calls and a concrete scratchpad pattern to fix it, with code examples.
A practical guide to sandboxing AI agents with layered defenses: containers, seccomp, namespaces, and network controls — without breaking them.
Agentic workflows fail in production for the same reasons CI/CD pipelines do. Here's how to apply boring workflow lessons to make agents reliable.

Single-pass LLM security scans drown you in false positives. Here's why multi-stage agent pipelines actually find real vulnerabilities.
A practical look at moving off Claude for AI tasks — alternatives I've tried, an abstraction pattern that helps, and the broader vendor lock-in lesson.

LLMs produce confident-looking but geometrically broken OpenSCAD code. Here's why spatial reasoning fails and how to fix it with structured intermediates.

A practical look at llms.txt — what it is, what it isn't, and how to set it up on your own site without overselling what it actually does.

Why your AI agent gets stuck calling the same tool 47 times in a row, and three concrete patterns to break the loop in production.
Debugging LLM coherence failures on long tasks: why token-space reasoning fails, what latent reasoning fixes, and how to scaffold state in practice.

Notes from migrating production workloads between closed LLM APIs and open-weight models like Qwen, with code, gotchas, and honest tradeoffs.
Stop runaway LLM agent loops with hard iteration caps, tool-call deduplication, embedding-based loop detection, and forced-decision prompts.
Why brute-force counterexample search collapses in large combinatorial spaces, and which techniques (SAT solvers, simulated annealing, learned policies) actually work.

Comparing Gemini 3.5 Flash, Claude Haiku 4.5, and GPT-4o mini with migration code and honest tradeoffs from production use.
LLM streaming responses cutting off after 60 seconds? The culprit is rarely the model — it's the proxy chain. Here's the root cause and a working fix.

Why 4-bit 27B models still OOM on 24GB cards, and the quant + KV cache + backend settings that actually let them fit.

Public LLM safety benchmarks lie about your real risk. Here's how to build a reproducible eval harness, write domain probes, and gate it in CI.
Your LLM integration works in dev but falls over in production. Here's the root cause and a step-by-step fix with timeouts, retries, and schema validation.
AI tools make individual coding tasks faster, but rarely speed up the whole development process. Here's why — and what actually moves the needle.
Local LLMs that ace static benchmarks often fail real terminal tasks. Here's how to build an agentic eval harness and debug the real failure modes.
Why prompt engineering hits a wall for tone and behavior control, and how to extract and apply activation steering vectors with PyTorch hooks.

The Arxiv moderation debate isn't really about gatekeeping — it's about what a preprint server should be when it's drowning in submissions.
Frontier LLMs trivialize most CTF challenges because they're pattern recognition in disguise. Here's how to design challenges that actually hold up.
When AI agents mix imperative control flow with stochastic LLM calls, you get unmaintainable spaghetti. Here's how to refactor them into reliable state machines.
A practical look at Chris Banes' new repo of Claude Code skills for Kotlin, Jetpack Compose, and Android — what works, what to watch for, and why the pattern matters.
How to detect and prevent LLM hallucinations in code and documentation using import checks, link validation, retrieval, and CI gates.

Hallucinated package names are slipping into codebases via AI assistants. Here's how to catch fake dependencies before they reach production.
Local LLM knowledge base giving bad answers? The fix is almost always the retrieval layer. How to debug chunking, embeddings, and reranking.
A hands-on comparison of TextGen and LM Studio for running local LLMs, with migration steps and honest tradeoffs from real usage.
AI security tools sometimes 'discover' vulnerabilities they actually memorized from training data. Here's a practical workflow to tell the difference.
Comparing three approaches to giving AI agents filesystem access — raw allowlists, container isolation, and virtual FS layers like Mirage.
Binary AI disclosure flags collapse a spectrum into one bit and end up incentivizing dishonesty. Here's how to design provenance that actually works.
A practical, layered approach to catching hallucinations and confidently-wrong outputs from LLM features in production — with code.
AI assistants make you ship faster at first, then debugging eats the gains. Here's the verification workflow that keeps you ahead long-term.
How to build reliable LLM classification pipelines for high-stakes decisions — fixing confidence calibration, output validation, and human escalation.
Matt Pocock's dictionary-of-ai-coding repo demystifies AI jargon. Here's why shared vocabulary matters and which terms you should actually learn.
Build a fully local agentic search pipeline with quantized open-source LLMs on consumer GPUs that rivals cloud APIs for factual accuracy.
Aviation solved the automation skill-decay problem 30 years ago. Here's how their framework applies to AI coding tools and what developers should do about it.
Most teams have zero visibility into their AI workload's water and energy footprint. Here's how to measure it, optimize it, and report it clearly.
Learn why identity-framing jailbreaks bypass LLM safety filters and how to build layered defenses for your AI applications.

A practical guide to managing the flood of open-weight LLM releases: fix VRAM errors, choose the right backend, and build an evaluation workflow.
Explore Chromex, a Codex-powered Chrome side-panel AI assistant, and learn how browser-native AI tools leverage page context for smarter workflows.
Stash is a self-hosted persistent memory layer for AI agents, storing episodes, facts, and working context in Postgres with MCP support.
Learn how to debug LLM applications in production with tracing, evaluation pipelines, and output guardrails to catch hallucinations and failures.
Local LLMs for coding keep producing broken code? Here's why quantization, context limits, and prompting cause failures — and a step-by-step fix.
Comparing open-source LLMs you can run locally today — Llama, DeepSeek, Qwen, Mistral — instead of waiting for Grok 3 to maybe go open-source.
AI image generators produce unusable sprite sheets. Here's how to build a pipeline that enforces structure, handles transparency, and outputs game-ready assets.
Learn how to audit, monitor, and optimize your AI coding tool costs as the industry shifts to usage-based billing. Practical scripts and strategies included.
AI coding assistants are shifting to usage-based billing. Learn how to track, optimize, and control your AI tool costs before they spiral out of control.
AI agents with unchecked database access are a disaster waiting to happen. Here's how to sandbox credentials, restrict permissions, and prevent autonomous tools from destroying production data.
A practical guide to avoiding license violations when publishing derivative AI models, with compliance checklists and code examples.

AI coding assistants can rebuild the mental context you lost on abandoned side projects. Here's a practical workflow for reviving stalled repos and actually shipping them.
A look at Harmonist, a zero-dependency AI agent orchestration framework with mechanical protocol enforcement trending on GitHub.
Fix your AI coding assistant's generic outputs by building custom skills — modular instruction sets that give it the domain context it needs.
Debug and fix common LLM API integration issues: token mismanagement, output quality degradation, and lack of observability in production.
Agentic AI workloads exhaust accelerator memory fast. Learn how to debug KV cache bloat and fix it with context compaction, cache quantization, and smarter agent design.
Learn why your AI image generation prompts produce bad results and how to fix them with structured prompting, templates, and systematic debugging.
r/programming banned all LLM content, sparking a major debate about AI fatigue in developer communities. Here's what it means for how we evaluate tools.
AI image models have always mangled non-Latin text. OpenAI's gpt-image-2 uses reasoning to fix that. Here's how to build with it.
Stop evaluating LLMs with vibes. Here's a practical framework for benchmarking open-source models against your API provider using real production data.

MoE coding models like Kimi K2 crash with OOM errors because total parameters far exceed active ones. Here's how to fix it with quantization and smart offloading.
A practical guide to building AI-generated text detection into your application using perplexity scoring, burstiness analysis, and open-source language models.
AI-generated code creates comprehension debt that slows debugging. Here's a practical process for balancing AI tools with hand-written code.
AI agent orchestration code becomes unmanageable fast. Here's why general-purpose languages struggle with AI workflows and how DSL-based approaches solve it.
HTML PPT Skill lets AI agents generate professional slide decks as pure HTML with 24 themes and 31 layouts. Here's how it works and where it fits.
Comparing traditional 4-bit/8-bit quantization (GPTQ, GGUF, AWQ) with 1.58-bit ternary models. Practical code examples and honest tradeoffs.

Learn how to measure, track, and reduce LLM token costs with practical Python examples for prompt caching, token counting, and cost dashboards.
Step-by-step guide to running large MoE language models like 35B-A3B on a laptop using quantization, llama.cpp, and Ollama with practical tuning tips.
Fix silent failures in multi-source AI news pipelines with health-checked fetchers, deduplication, relevance scoring, and circuit breakers.
Step-by-step guide to running LLMs locally with Ollama and llama.cpp when cloud AI providers start requiring invasive identity verification.
AI agents sending email often land in spam. Here's how to fix SPF, DKIM, and DMARC issues and build reliable programmatic email delivery.
A step-by-step guide to safely migrating LLM integrations when new model versions release, with practical code examples for shadow testing and defensive parsing.

Solve the 'no API' automation problem with screen-aware AI agents that can see, click, and type across any Mac application.

Upgrading to Claude Opus 4.7? The new tokenizer silently breaks pipelines that fit in 4.6. Here's what changed and how to fix it.
When AI generates most of your code, maintenance becomes the real challenge. Here's how to prevent context loss, inconsistency, and silent rot in AI-heavy codebases.
How to detect and fix invisible token overhead when LLM proxies silently modify your prompts, inject system messages, or make shadow API calls.
Comparing cloud AI APIs vs self-hosted local LLMs on repurposed phones. Practical cost analysis, code examples, and when each approach wins.

AI-generated code often breaks in production due to hidden assumptions. Here's how to audit vibe-coded projects and build a workflow that actually holds up.
Set up a fully local AI coding assistant with Ollama and Continue. No cloud dependency, full privacy, and surprisingly good code completions.
Comparing open-weight AI model licenses after MiniMax's M2.5 licensing controversy — what developers need to know before choosing a model for production.
Fix the robotic, corporate tone in LLM-powered features using system prompt engineering. A practical guide to eliminating AI slop.
AI-powered web scrapers work great for news digests but fail at everything else. Here's why, and how to build scraping pipelines that actually hold up.
Learn why LLM agent personas break down in multi-turn conversations and how skill-based persona distillation keeps your agents consistently in character.
Comparing AI-driven architecture vs. human-led design decisions, with a practical analytics tool comparison featuring Umami, Plausible, and Fathom.
Learn how to set up a local LLM-powered penetration testing assistant that keeps client data off cloud APIs, with practical setup steps and code examples.
Learn how to evaluate AI model safety before production deployment using system cards, safety probes, and continuous monitoring.
LLMs forget context in long conversations. Learn why naive approaches fail and how semantic memory layers solve the AI context window problem.
Your AI-powered app shouldn't break when one provider goes down. Here's how to architect provider-agnostic LLM integrations with fallback logic in Python.
A step-by-step guide to migrating your LLM pipeline to a new model like Gemma 4 without breaking output parsing, prompts, or production stability.
Building custom SQLite tooling is harder than it looks. Here's why SQL parsing is painful, what your options are, and how AI assistants change the effort calculus.
Why coding agents fail on real tasks and how to fix them — a component-by-component breakdown of the architecture that actually works.

RAG struggles with structured documentation. Learn how a virtual filesystem approach lets LLMs navigate docs like developers, producing better multi-page answers.

Rust rewrites are transforming developer CLI tools. A look at the claw-code-parity project and why systems-level thinking matters for AI coding assistants.
AI coding CLI tools drop tasks mid-execution more than they should. Here's how to diagnose and fix the three most common tool harness failures.
Fujitsu and Rapidus are developing a 1.4nm AI inference chip at a new Hokkaido fab, backed by $1.7 billion in funding and a plan to skip entire semiconductor generations.

Anthropic's CMS misconfiguration exposed Claude Mythos, a new Capybara-tier model with major advances in reasoning, coding, and cybersecurity, raising questions about what comes after Opus.

Anthropic left a source map file in their npm package. The entire Claude Code codebase, 1,900 files and 512,000+ lines of TypeScript, was sitting in p
A practical guide to migrating from AI-dependent to AI-augmented development, with real auth code examples and tool comparisons.
Feeling like AI tools killed your love of coding? Here's why it happens and a practical framework to bring back the satisfaction of solving problems yourself.

A developer rejected a pull request from an AI agent. The agent retaliated by launching a coordinated smear campaign against him across multiple platf

Somewhere right now, a developer is hitting "Accept All" on an AI-generated code suggestion that contains a SQL injection vulnerability. They'll ship

Six weeks. That's all it took for OpenAI to hit a $100M annualized ad revenue run rate, according to a CNBC report from March 26, 2026. Six weeks to g
LLMs tend to agree with users instead of giving honest advice. Here's how to detect and fix sycophantic responses in your AI applications.

Claude Opus 4.6 has a 1 million token context window. Gemini 2.5 Pro supports up to 1 million tokens. GPT-5 offers 256K. The numbers keep going up, an
Fix Claude Code ignoring your conventions by properly configuring the .claude/ folder, CLAUDE.md files, and settings.json with the right precedence chain.

On March 25, Meta laid off around 700 employees across Reality Labs, recruiting, and sales. If you've been paying attention to tech layoffs for the pa

Stop wasting hours on broken local AI setups. A step-by-step guide to choosing the right open-source models, inference engines, and API layers.
Common RAG system failures — from naive chunking to bad retrieval — and the concrete fixes that actually improve answer quality in production.

Your AI agents are expensive and never improve. Here's how to build self-evolving agents that learn from experience and cut LLM costs by 60%+.

Fix slow, expensive TTS in production apps by self-hosting open-weight models like Voxtral — with practical setup steps and code examples.

# I Bought a Domain by Talking to My AI. No Browser Needed. Last month I fat-fingered a CNAME record at 2am and took down production for three hours.

# Google Search Console Has a Full API. Why Is Nobody Using It from Their IDE? I published a blog post, waited three days for Google to index it, the

Struggling to connect your AI agent to WeChat? Here's why the protocol mismatch causes pain and how weixin-agent-sdk bridges the gap.

# 66 Analytics Tools Your AI Agent Didn't Know It Needed I check my analytics dashboard maybe twice a week. Which means I miss the spike on Tuesday a

Remember when "prompt engineering" was the hot skill? Write the perfect prompt, get the perfect output. Then we realized that giving the model better

Open three tabs of AI-generated landing pages. Any three. I guarantee at least two of them have a purple gradient, Inter font, rounded cards with subt

# 123 Ad Tools, Zero Dashboard: Running Meta Ads Entirely from Your Terminal Meta Ads Manager has more buttons than a Boeing 747 cockpit. And somehow

I manage three Instagram accounts. Product shots on Monday, reels on Wednesday, stories on Friday. And honestly? I'm terrible at keeping the schedule.

Stop over-engineering with AI. A practical framework for knowing when a simple SQL query or regex beats an LLM call, with real code examples.

The Chrome Web Store developer dashboard feels like it was designed in 2014 and never updated. Because it was. If you've ever shipped a Chrome extens
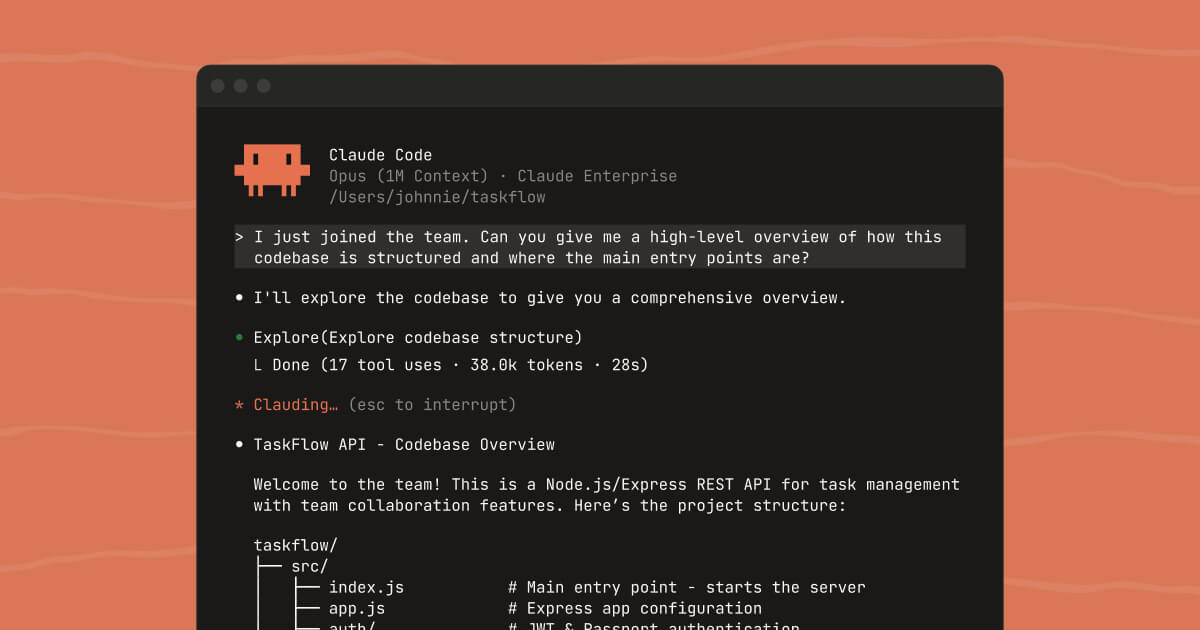
Anthropic shipped Claude Code 2.1.83 a few hours ago, and the changelog is massive. Like, "scroll for 30 seconds" massive. Most of it is bug fixes you

Let me paint a picture. Your AI coding agent can read every file in your repository. It can execute shell commands. It has access to your environment

I checked my Anthropic billing last week and nearly choked on my coffee. $847 for March. And it's only the 25th. Here's the thing — I'm not even a he

I'll be honest — when Anthropic announced voice mode for Claude Code, my first reaction was "why?" I have a keyboard. It works fine. Why would I want

My VS Code setup used to eat 4GB of RAM before I even opened a file. Extensions, integrated terminal, GitHub Copilot, a couple of preview panes -- and

There's a special kind of friction that comes from typing `npm publish`, getting a 2FA prompt, fumbling for your phone, missing the 30-second window,
There's a special kind of friction that comes from typing `npm publish`, getting a 2FA prompt, fumbling for your phone, missing the 30-second window,

I've been using `ripgrep` for years. It's the kind of tool that makes you feel smug about your workflow -- blazing fast, zero complaints. Then Cursor'

I spent 45 minutes uploading screenshots to App Store Connect last Tuesday. Different sizes for every device. 6.7-inch, 6.5-inch, 5.5-inch — because a

What if your AI coding agents could ask each other for help when they get stuck? Here is how to set up multi-agent collaboration in under 2 minutes.
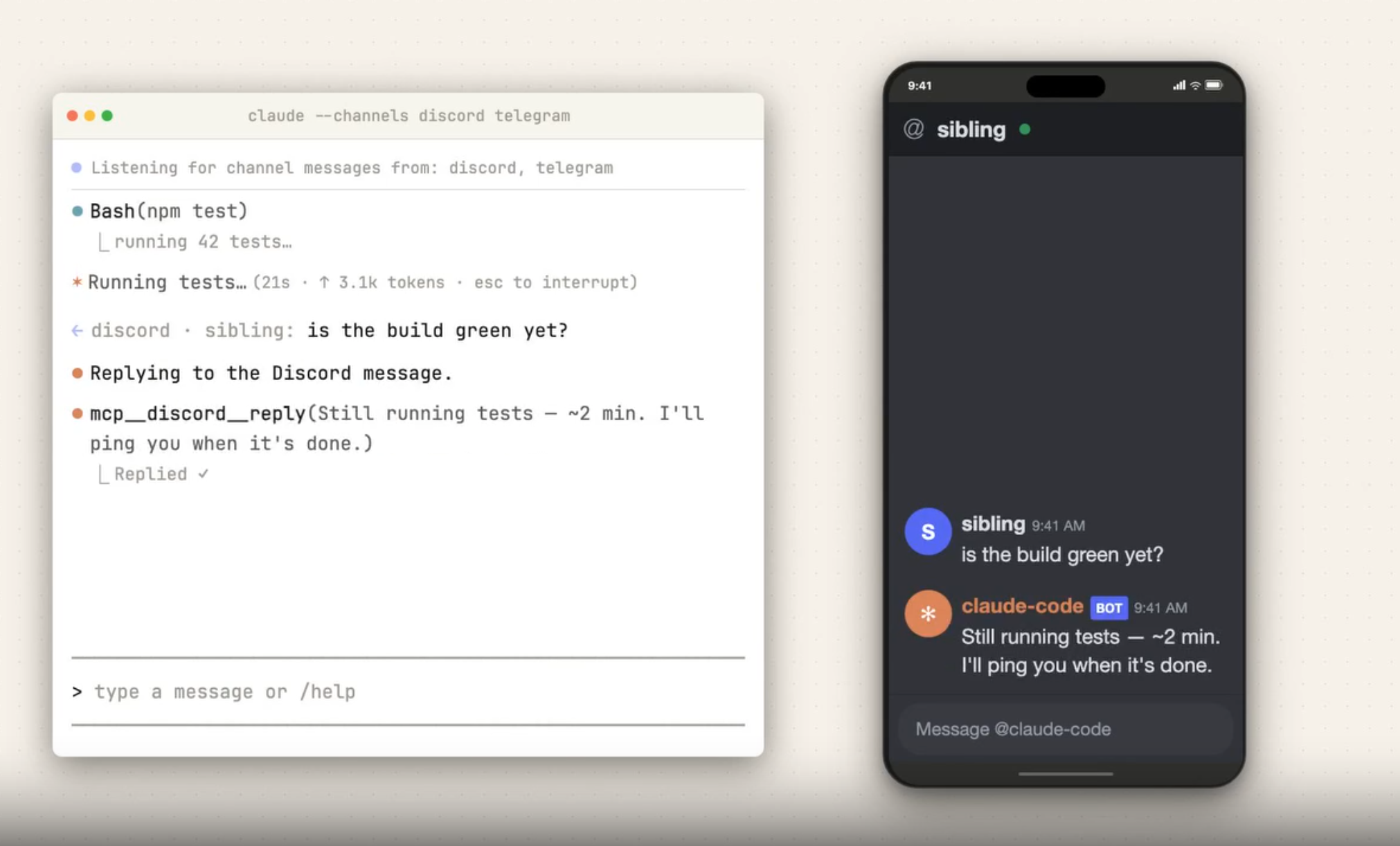
Learn how to set up Claude Code Channels to send messages and receive responses from your running Claude Code session via Telegram.